

Do you want to save data to RDBMS?
It’s not that hard.
So today I’m going to show you how easy it can be done using Diggernaut’s Compile Service.
Stage One: preparation.
This is test configuration you can use as a sample for education, its fully working example and doesn’t break any TOS. So its safe to use it in any country.
---
do:
- walk:
to: 'https://www.diggernaut.com/sandbox/'
do:
- find:
path: 'div:nth-child(6) .result-content'
do:
- find:
path: h3
do:
- parse
- variable_clear: name
- variable_set: name
- find:
path: p
do:
- parse
- variable_clear: description
- variable_set: description
- find:
path: 'tbody > tr'
do:
- parse
- object_new: item
- variable_get: name
- object_field_set:
object: item
field: name
- variable_get: description
- object_field_set:
object: item
field: descr
- object_new: date
- find:
path: '.col5 > .nowrap:nth-child(1)'
do:
- parse
- object_field_set:
object: date
field: date
- find:
path: '.col5 > .nowrap:nth-child(2)'
do:
- parse
- object_field_set:
object: date
field: date
joinby: " - "
- find:
path: .col6
do:
- parse
- normalize:
routine: replace_substring
args:
\s*(\d+)A: 's'
- object_field_set:
object: date
field: time
- object_save:
name: date
to: item
- object_save:
name: itemResulting dataset has the following structure:
item: [
{
"name":"",
"descr":"",
"date": [
{
"date":",
"time":""
}
...
...
]
},
...
...
]
Let’s prepare our database. Digger can save data to MySQL, Microsoft SQL and PostgreSQL. So we need to create database and tables for our data.
MYSQL
CREATE DATABASE `digger`;
CREATE TABLE `items` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`name` VARCHAR(50) NULL DEFAULT NULL,
`descr` TEXT NULL,
PRIMARY KEY (`id`)
)
COLLATE='utf8_general_ci'
ENGINE=InnoDB;
CREATE TABLE `dates` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`item_id` INT(11) NOT NULL,
`date` VARCHAR(50) NULL DEFAULT NULL,
`time` VARCHAR(50) NULL DEFAULT NULL,
INDEX `Index 1` (`id`),
INDEX `FK__items` (`item_id`),
CONSTRAINT `FK__items` FOREIGN KEY (`item_id`) REFERENCES `items` (`id`) ON UPDATE NO ACTION ON DELETE NO ACTION
)
COLLATE='utf8_general_ci'
ENGINE=InnoDB;
MS SQL
CREATE DATABASE `digger`;
CREATE TABLE `items` (
id INT NOT NULL IDENTITY(1,1) CONSTRAINT pk_items_pid PRIMARY KEY,
`name` VARCHAR(50),
`descr` TEXT
);
CREATE TABLE `dates` (
id INT NOT NULL IDENTITY(1,1) CONSTRAINT pk_dates_pid PRIMARY KEY,
item_id int CONSTRAINT fk_item_id FOREIGN KEY(item_id) REFERENCES items(id),
date TEXT,
time TEXT
);
PostgreSQL
CREATE DATABASE digger;
CREATE TABLE items (
id SERIAL PRIMARY KEY,
name varchar(50),
descr text,
);
CREATE TABLE dates (
id SERIAL PRIMARY KEY,
date varchar(50),
time varchar(50),
item_id integer REFERENCES items (id),
);
Now let’s compile our digger.
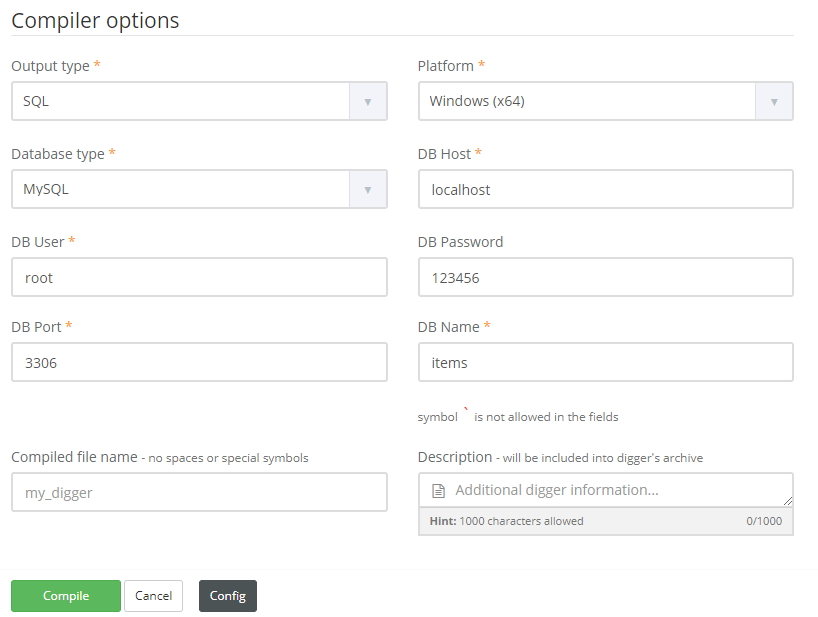
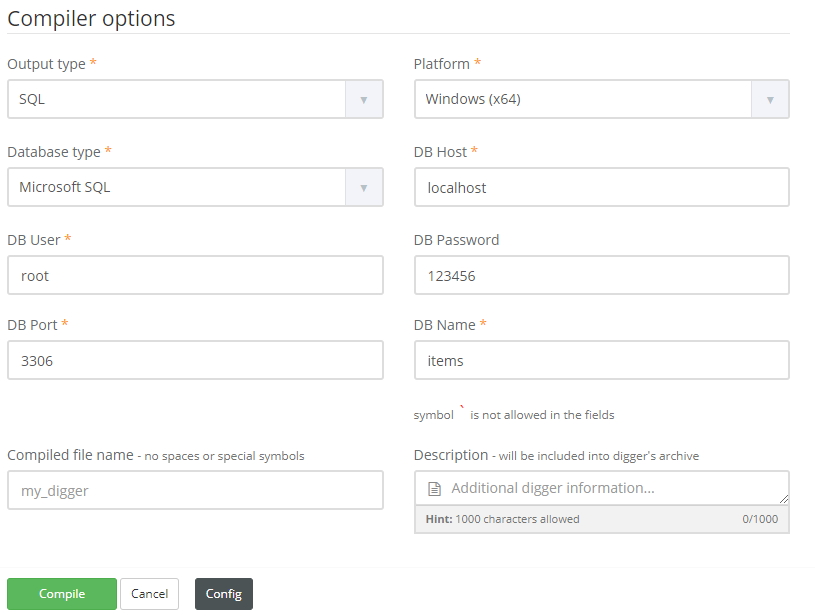
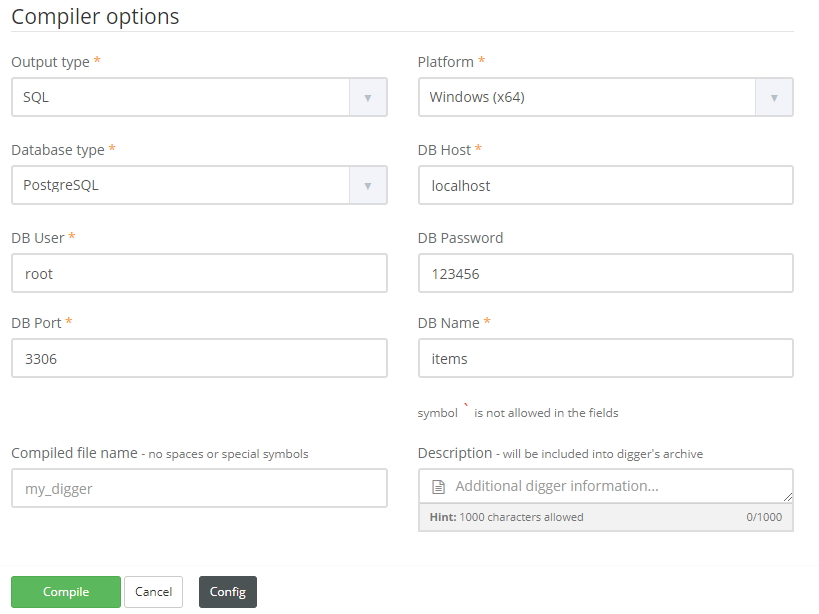
Download it and run. Once the job is finished, you can see data in your DB. So now you can have your data flow directly from digger to your database without a hassle.
